
Import danych do bazy danych jest częstym zadaniem programisty. Niestety zadanie to często niesie ze sobą wiele wyzwań i obejmuje wiele dodatkowych zadań takich jak odkrywanie i wydobywanie danych z różnych źródeł, sprawdzanie poprawności, wzbogacanie, czyszczenie, normalizowanie i łączenie danych oraz ładowanie i organizowanie danych w bazach lub hurtowniach danych. Dodatkowym problemem jest często duży wolumen danych które muszą zostać zaimportowane.
AWS Glue rozwiązuje część z tych problemów.
AWS Glue
AWS Glue jest bezserwerową usługą integracji danych, która ułatwia odkrywanie, przygotowywanie i łączenie danych na potrzeby analiz, uczenia maszynowego i tworzenia aplikacji. AWS Glue zapewnia wszystkie możliwości potrzebne do integracji danych, dzięki czemu możesz rozpocząć analizę danych i oddanie ich do użytku w ciągu kilku minut, a nie miesięcy.
Praca z AWS Glue
Praca z AWS Glue składa się z trzech etapów. W pierwszym etapie AWS Glue odkrywa schemat danych do zaimportowania i zapisuje go do tabeli w AWS Glue Data Catalog. Zadanie to wykonywane jest poprzez crowlera.
W drugim etapie, na podstawie wygenerowanego schematu, AWS Glue wygeneruje skrypt zadania ETL job, które zaimportuje dane ze źródła, przekształci je i zapisze do miejsca docelowego.
Trzecim zadaniem AWS Glue jest uruchomienie wykonania utworzonego zadania, na podstawie wygenerowanego schematu i skryptu zadania.
Import danych z pliku CSV do bazy danych Postgres
1. Przygotowanie importowanego pliku
Jako przykładowy plik do importu użyty został plik title.basics.csv z tytułami filmów z bazy portalu IMDb, który pobrać można ze strony plików z danymi IMDb, dzięki uprzejmości IMDb (http://www.imdb.com). Używane za zgodą.
Pierwsze 10 wierszy z pliku wygląda następująco:
tconst;titleType;primaryTitle;originalTitle;isAdult;startYear;endYear;runtimeMinutes;genres
tt0000001;short;Carmencita;Carmencita;0;1894;\N;1;Documentary,Short
tt0000002;short;Le clown et ses chiens;Le clown et ses chiens;0;1892;\N;5;Animation,Short
tt0000003;short;Pauvre Pierrot;Pauvre Pierrot;0;1892;\N;4;Animation,Comedy,Romance
tt0000004;short;Un bon bock;Un bon bock;0;1892;\N;12;Animation,Short
tt0000005;short;Blacksmith Scene;Blacksmith Scene;0;1893;\N;1;Comedy,Short
tt0000006;short;Chinese Opium Den;Chinese Opium Den;0;1894;\N;1;Short
tt0000007;short;Corbett and Courtney Before the Kinetograph;Corbett and Courtney Before the Kinetograph;0;1894;\N;1;Short,Sport
tt0000008;short;Edison Kinetoscopic Record of a Sneeze;Edison Kinetoscopic Record of a Sneeze;0;1894;\N;1;Documentary,Short
tt0000009;short;Miss Jerry;Miss Jerry;0;1894;\N;40;Romance,Short
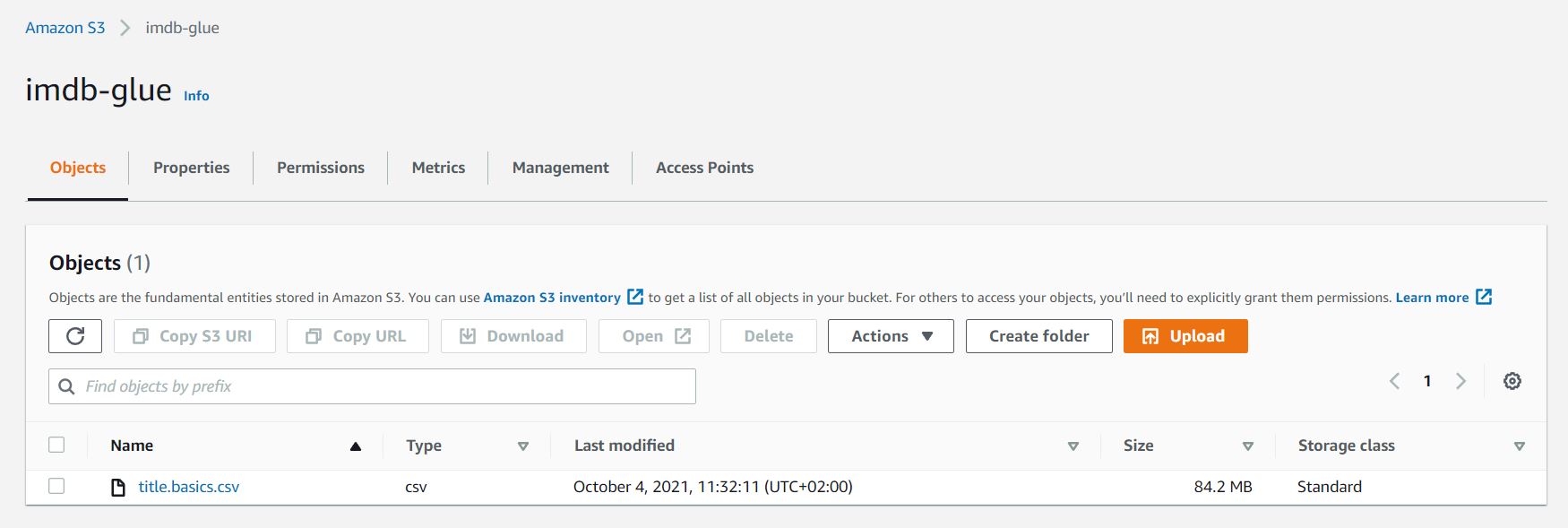
PLik title.basics.csv został umieszczony na S3 Bucket o nazwie imdb-glue
2. Utworzenie crawlera
Aby utworzyć crawlera w oknie AWS Glue wybieramy sekcję Crawlers i Add crawler.
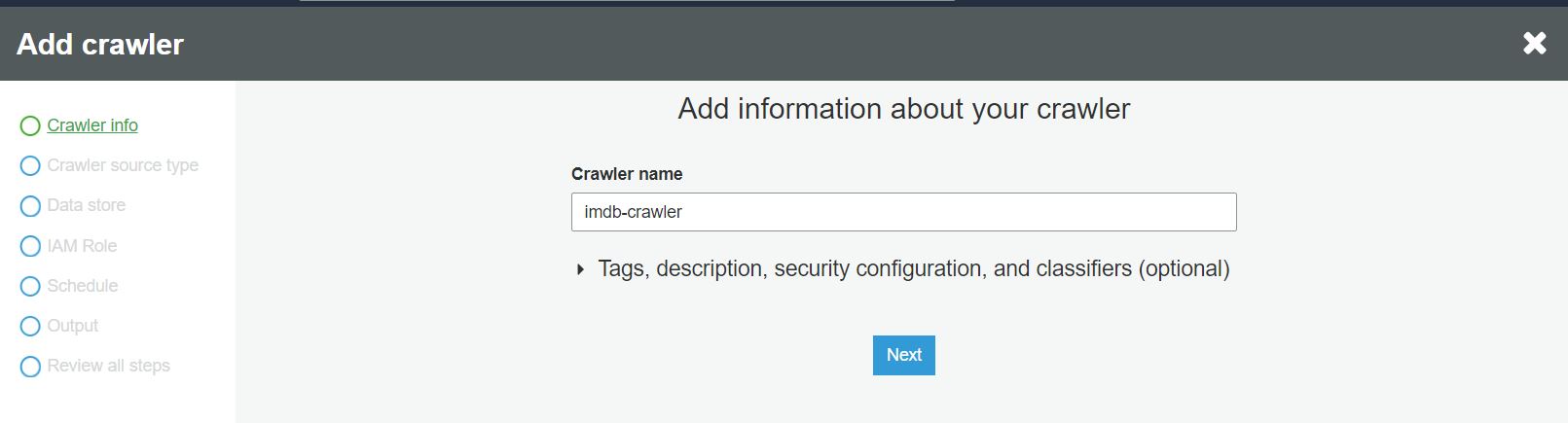
W pierwszym kroku kreatora tworzącego nowego crawlera definiujemy jego nazwę:
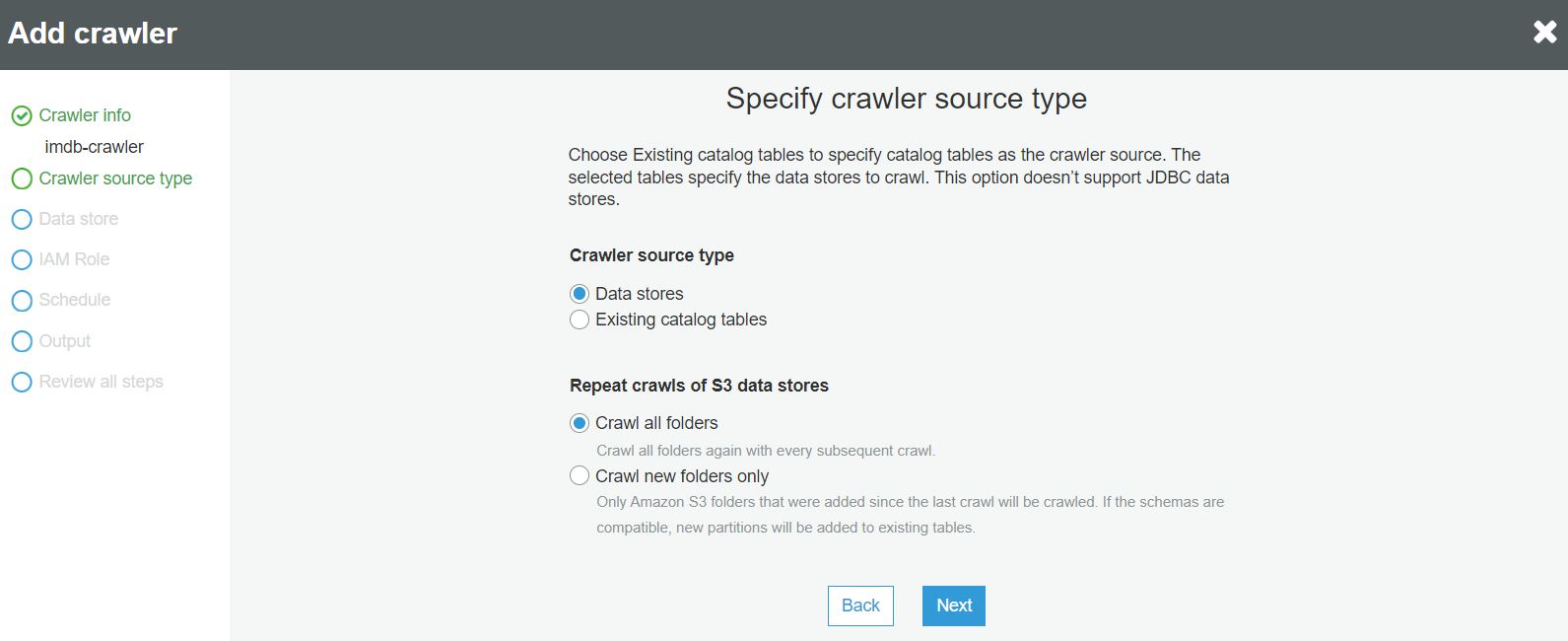
W następnym kroku określamy typ źródła dla crawlera:
W kroku definicji żródła danych wejściowych wybieramy ścieżkę do S3 bucket w którym znajduje się plik do importu:
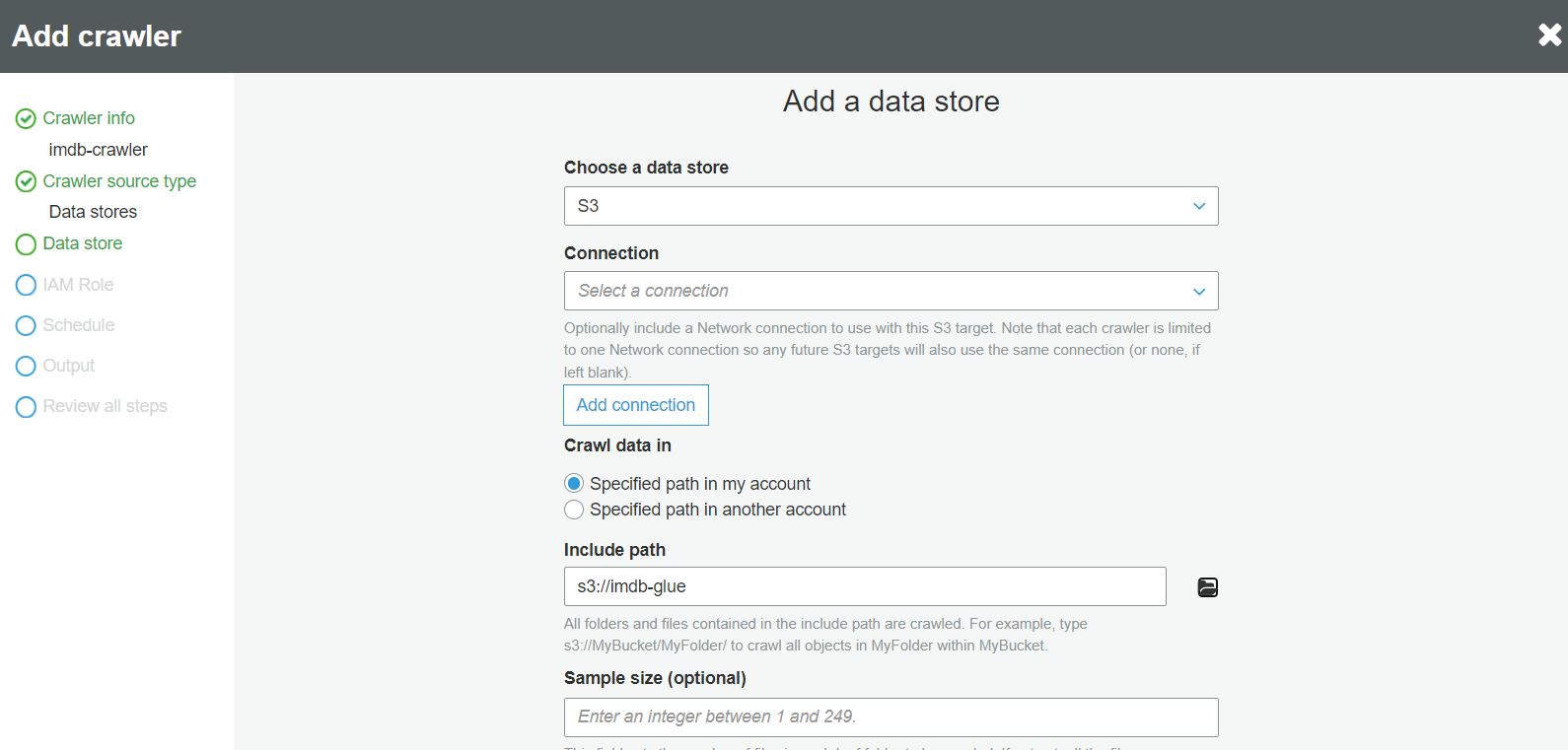
W kroku wyboru roli IAM wybieramy istnięjącą lub tworzymy nową rolę, która będzie umożliwi dostęp crawlerowi do importowanego pliku:
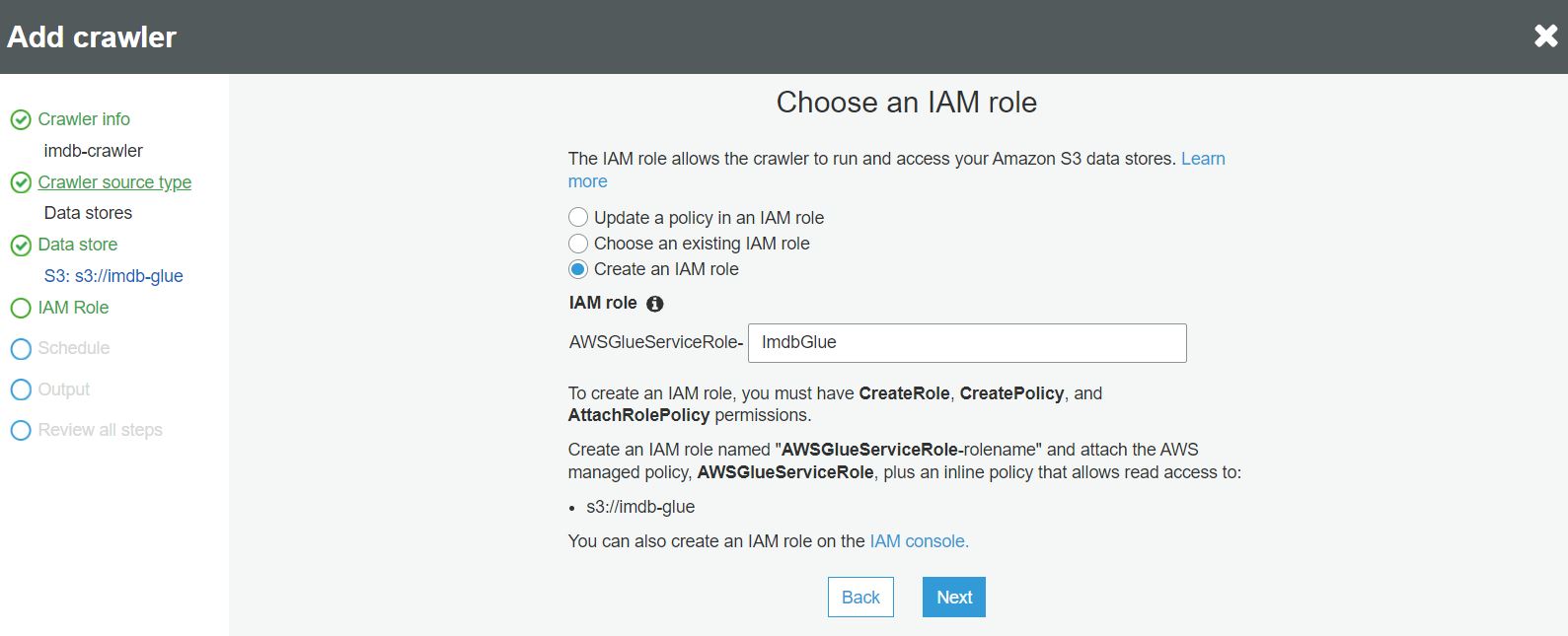
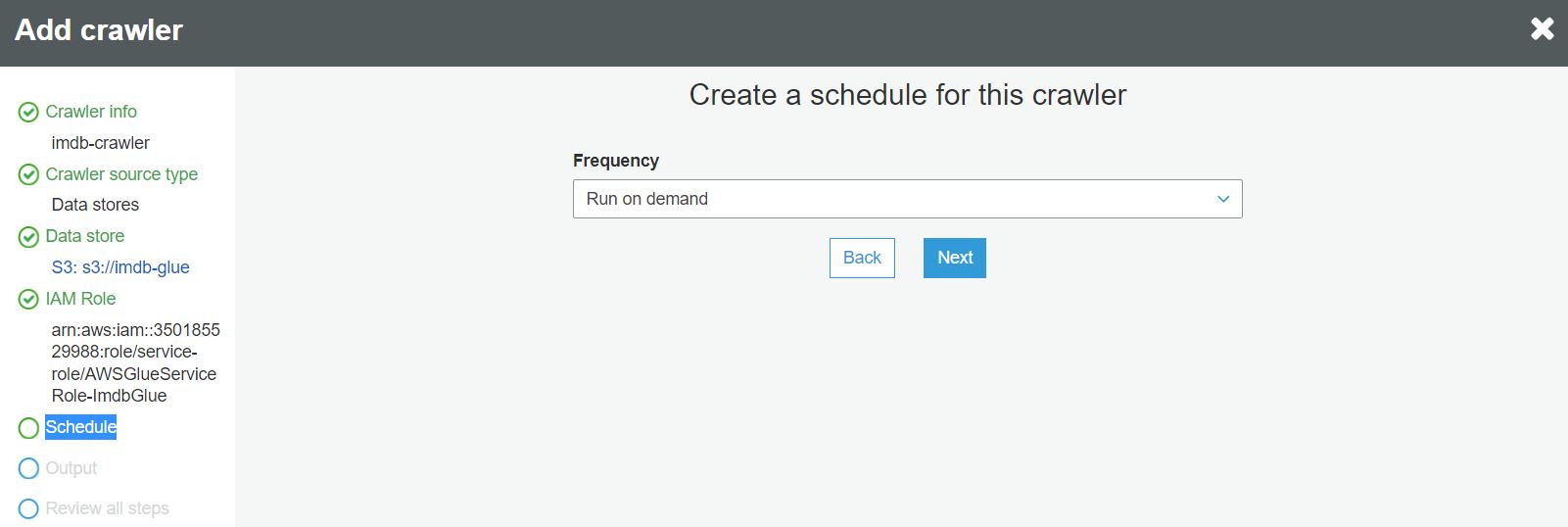
W kroku harmonogramu definiujemy jak często crawler ma być uruchamiany. W przykładzie wybieramy opcję uruchamiania na żądanie:
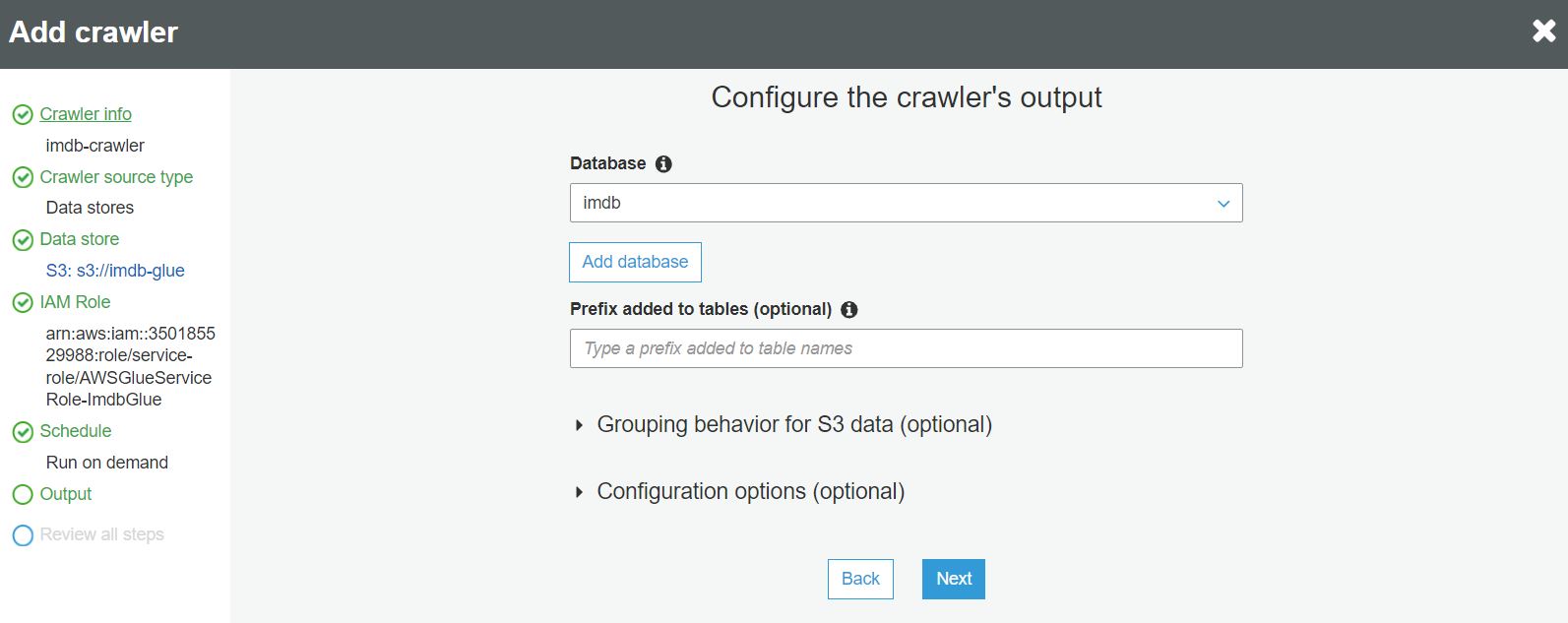
W kroku output wybieramy lub tworzymy bazę danych AWS Glue Data Catalog w której będą przechowywane odkryte przez crawlera metadane:
W ostatnim kroku możemy sprawdzić wprowadzone dane i zakończyć tworzenie crawlera:
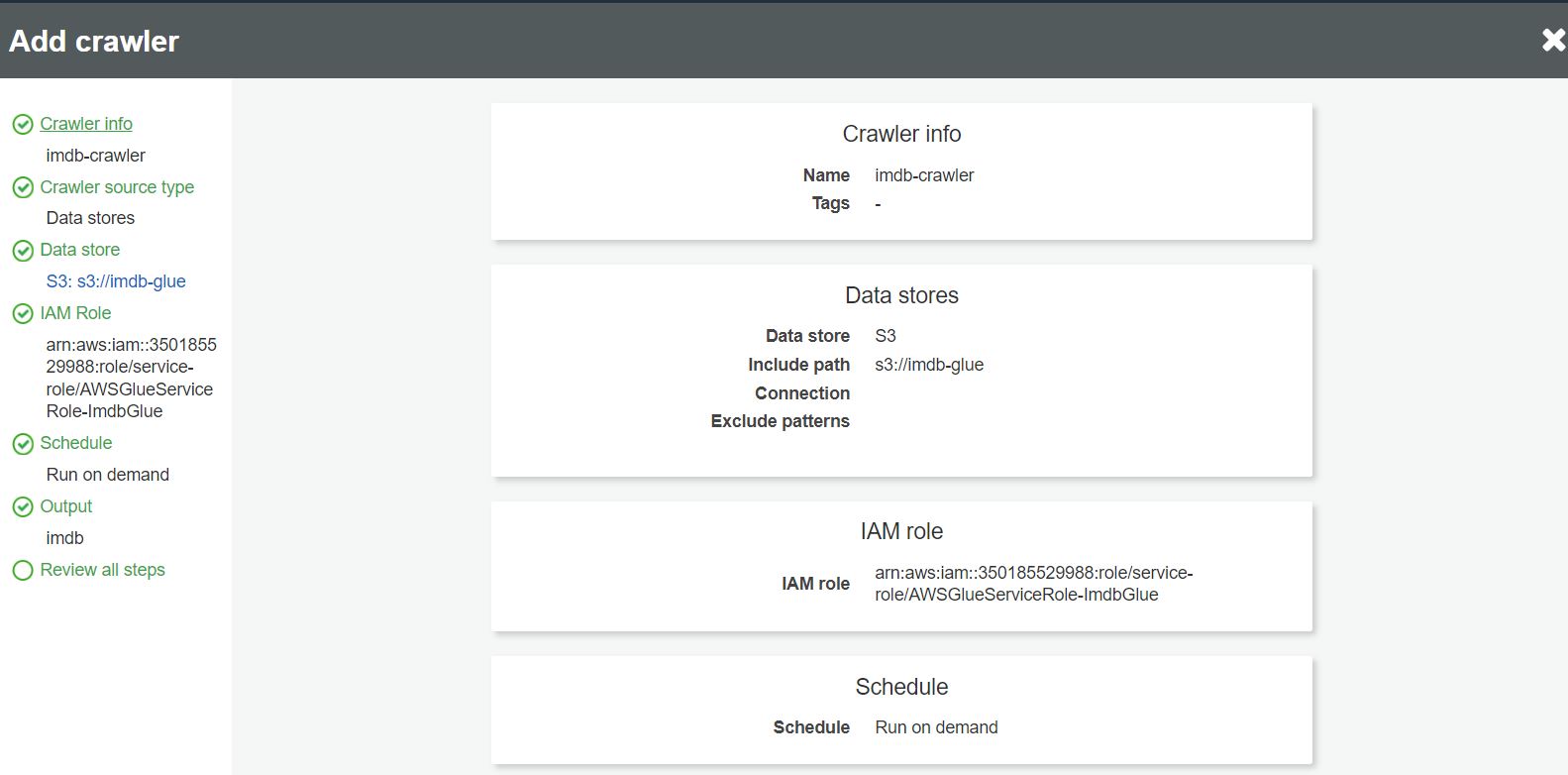
Po utworzeniu crawlera możemy go uruchomić guzikiem Run crawler.
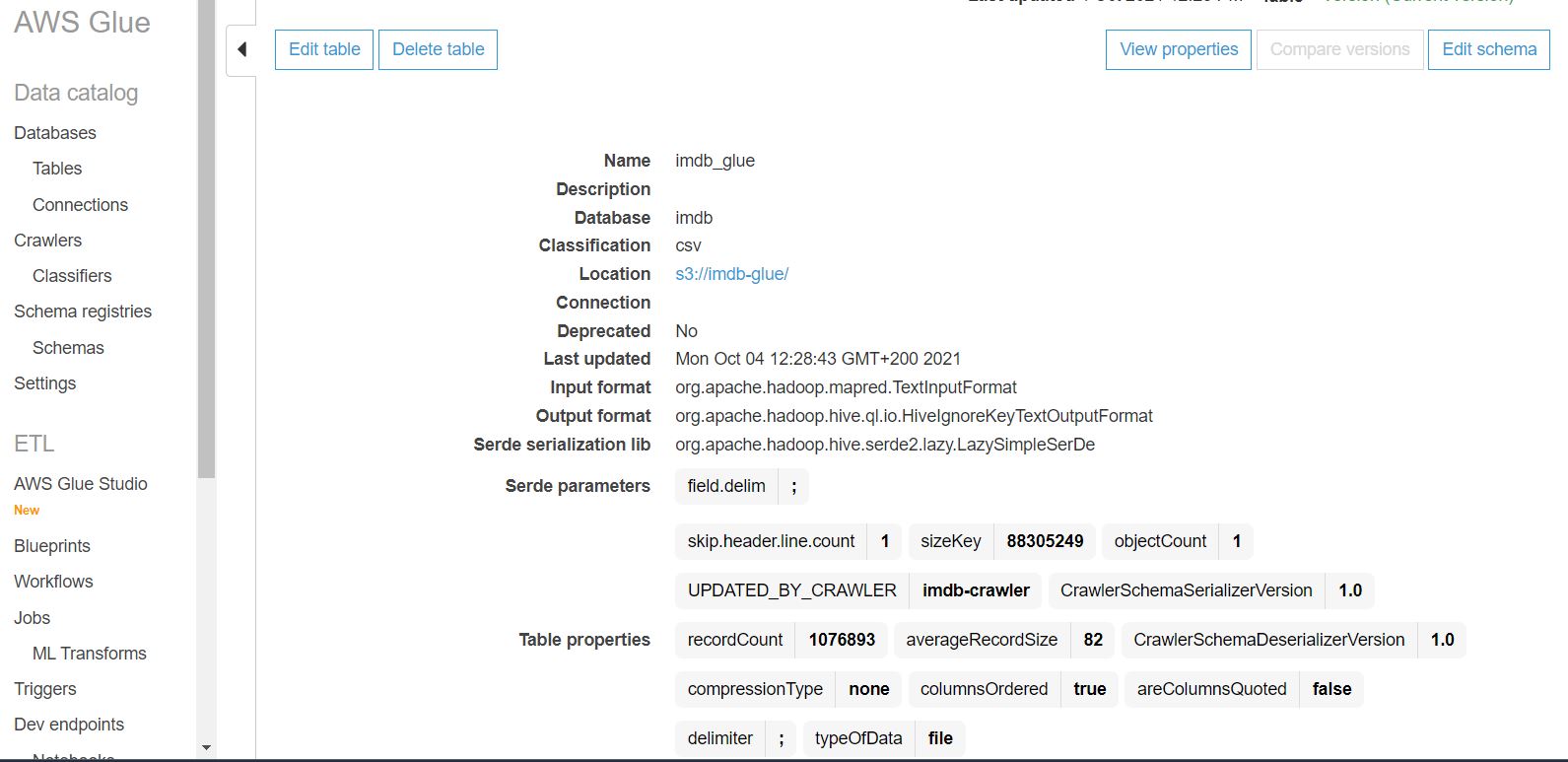
Wynikiem działania crawlera jest tabela utworzona w bazie AWS Glue Data Catalog, którą można podejrzeć w sekcji Databases->Tables:

Klikając w nazwę tabeli możemy podejrzeć wykryte metadane w niej zapisane:
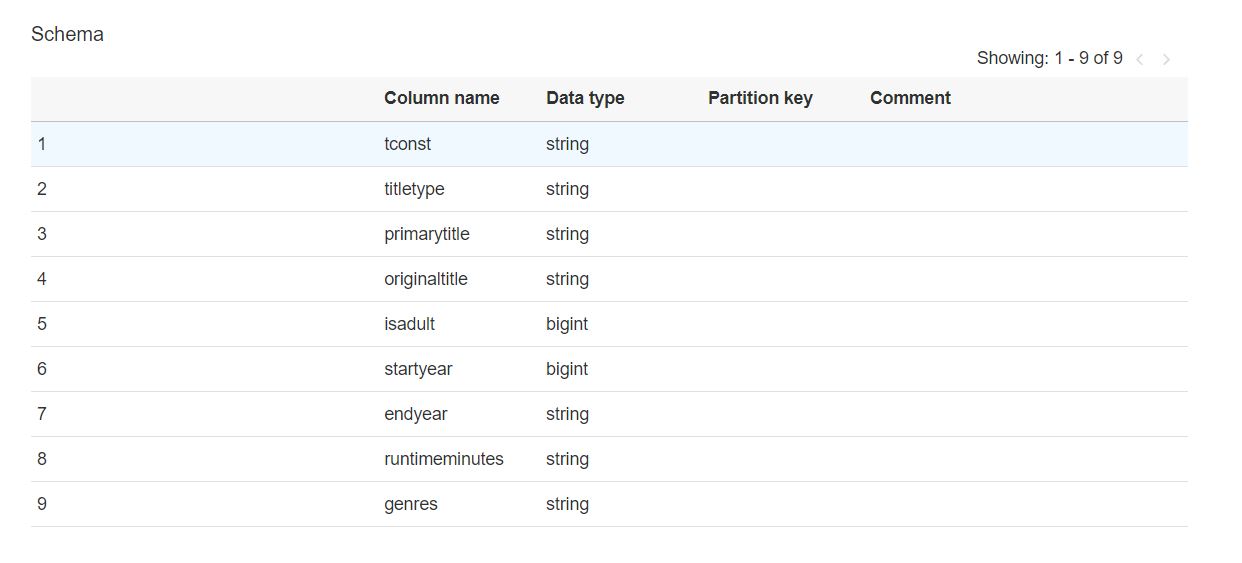
Oraz wykryty schemat pliku do importu:
3. Utworzenie joba AWS Glue
AWS Glue ma teraz schemat danych, które chcemy zaimportować. Następnym krokiem jest zdefiniowanie zadania (AWS Glue job) importu tych danych do bazy danych Postgres. AWS Glue job jest skryptem wykonywalnym przez Spark, który AWS Glue pomaga nam wygenerować.
Aby AWS Glue job mógł zostać wykonany to muszą zaotać spełnione pewne warunki: * VPC w którym znajduje się baza danych Postgres musi mieć możliwość komunikacji z S3 Bucket. * AWS Glue job musi posiadać dostęp do VPC w którym znajduje się baza danych Postgres.
Utworzenie VPC Endpoint dla S3
Aby VPC w którym znajduje się baza danych Postgres miała możliwość komunikacji z S3 Bucket, należy utworzyć VPC Endpoint dla S3. VPC Endpoint dla S3 umożliwia AWS Glue korzystanie z prywatnych adresów IP w celu uzyskania dostępu do S3 bez dostępu do publicznego Internetu.
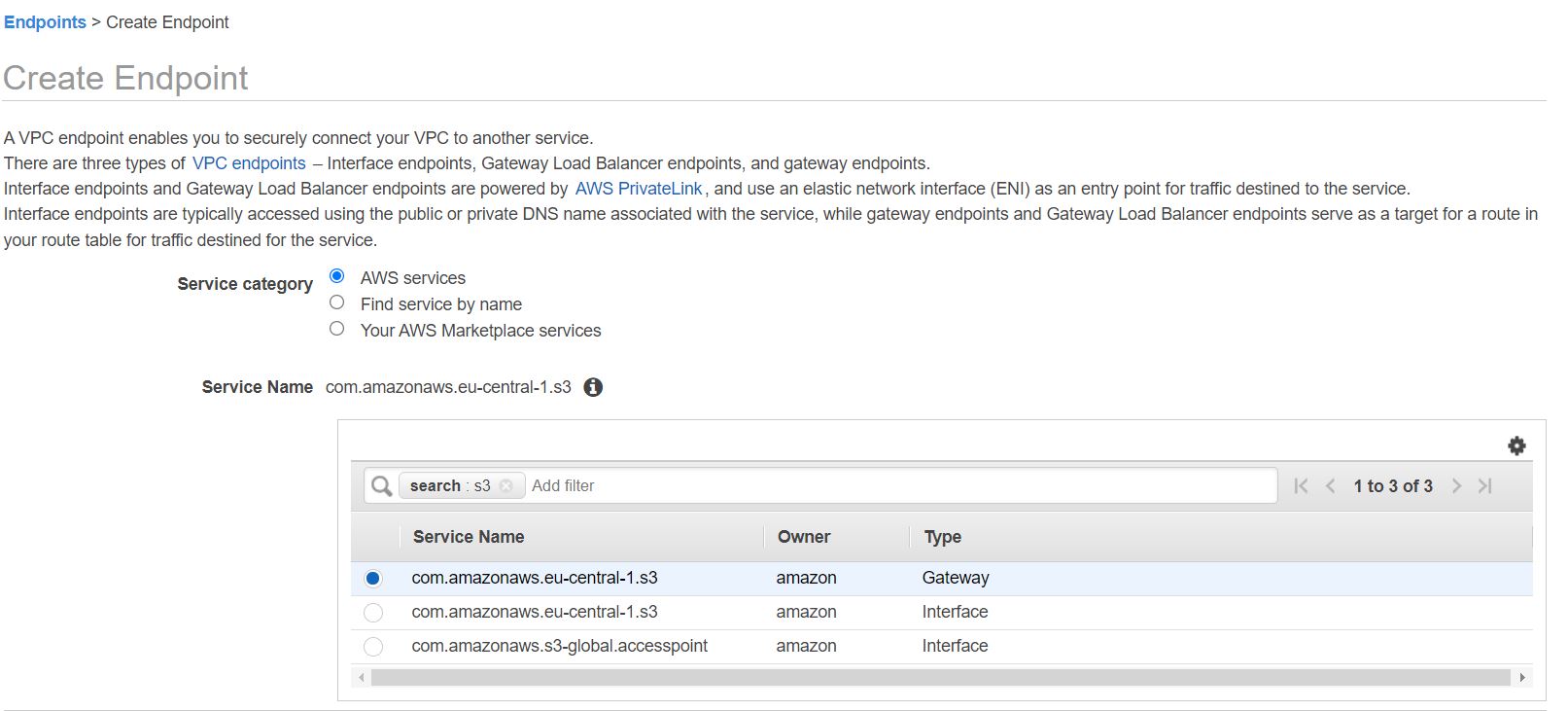
Aby skonfigurować dostęp do S3 w widoku VPC wybieramy sekcję Endpoints i naciskamy guzik Create Endpoint.
W sekcji Service category wybieramy wartość AWS services i w sekcji Service name wybieramy wartość com.amazonaws.eu-central-1.s3 z typem Gateway:
W sekcji VPC wybieramy identyfikator naszego VPC i zaznaczamy tablicę routingu dla tego VPC:
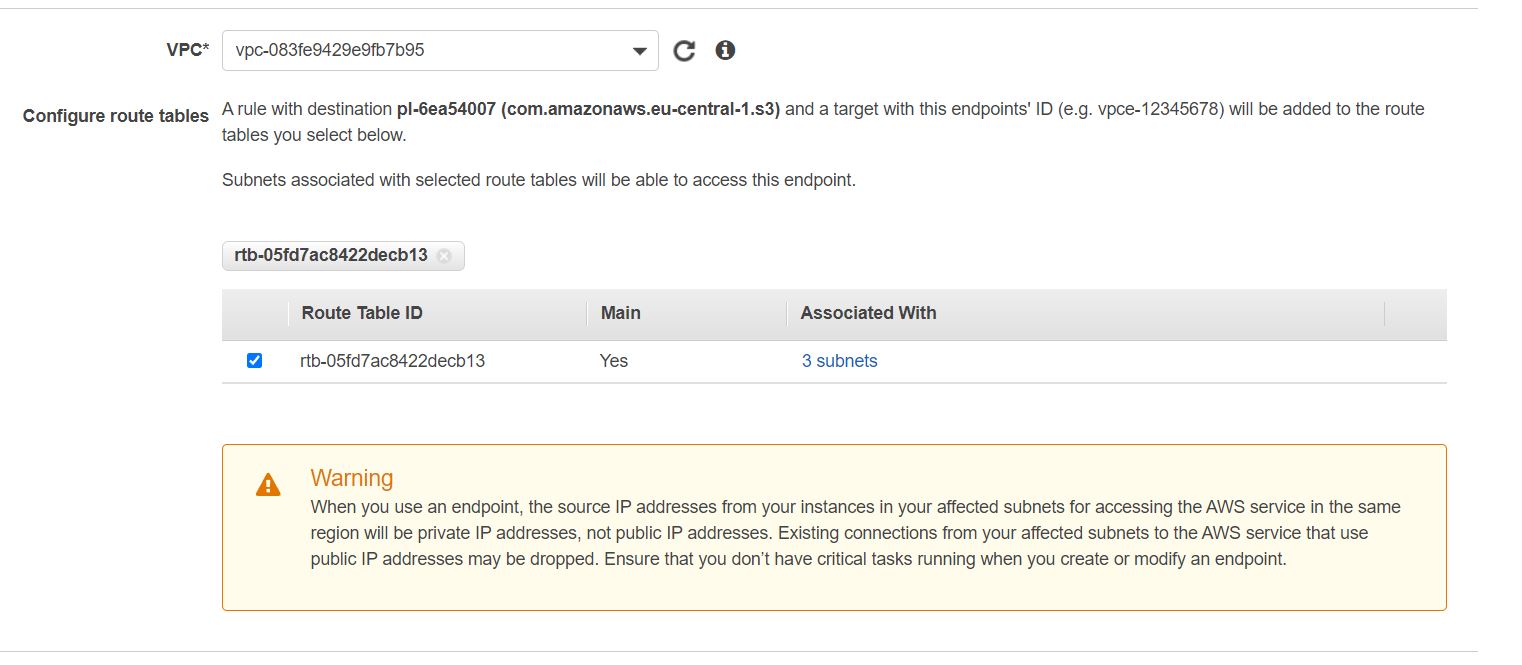
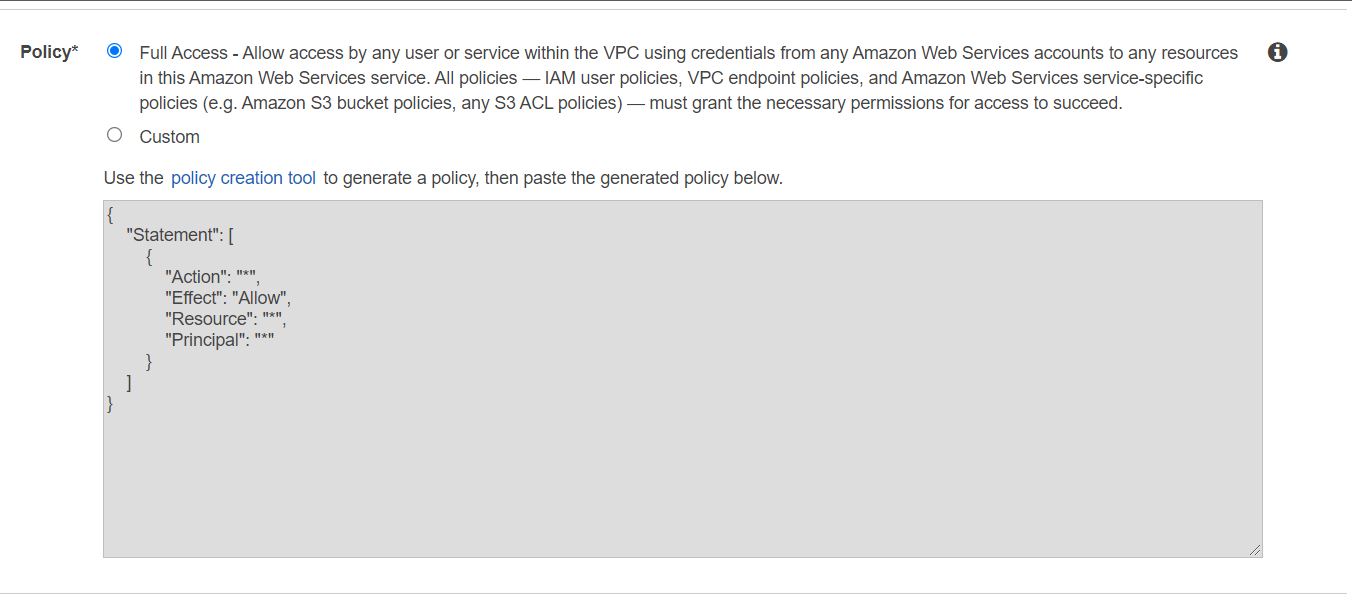
W sekcji Policy zostawiamy wartość Full Access:
Ustawienie dostępu AWS Glue JDBC Data Store do VPC z bazą Postgres
Aby umożliwić komunikację komponentów AWS Glue należy skonfigurować dla nich dostęp do bazy Amazon RDS. Aby to umożliwić należy stworzyć grupę zabezpieczeń z samoodnoszącą się regułą przychodzącą dla wszystkich portów TCP.
Grupę zabezpieczeń dla bazy Postgres konfigurujemy w widoku Amazon RDS -> Databases wybierając instancję naszej bazy Postgres i przechodząc do sekcji Security Groups w jej detalach. W sekcji Security Groups wybieramy grupę zabezpieczeń dla której chcemy mieć dostęp z AWS Glue i przechodzimy do jej detali w konsoli Amazon EC2.
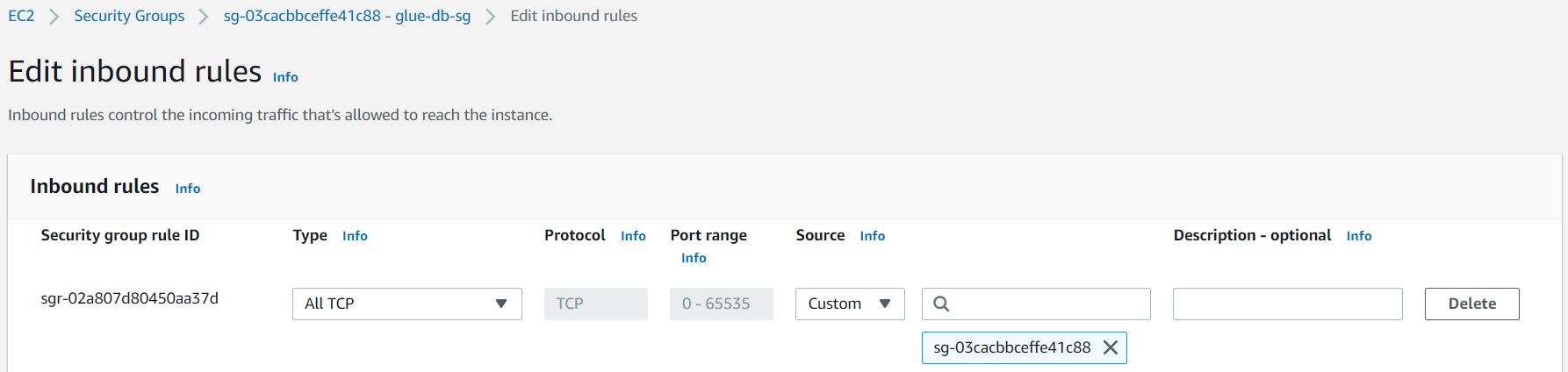
W zakładce Inbound rules dodajemy nową samoodnoszącą się regułę wybierając typ All TCP i Custom Source z identyfikatorem tej grupy zabezpieczeń jako wartość.
Dodanie połączenia do bazy Postgres
Połączenie do bazy danych dodajemy w widoku AWS Glue w sekcji Databases -> Connections.
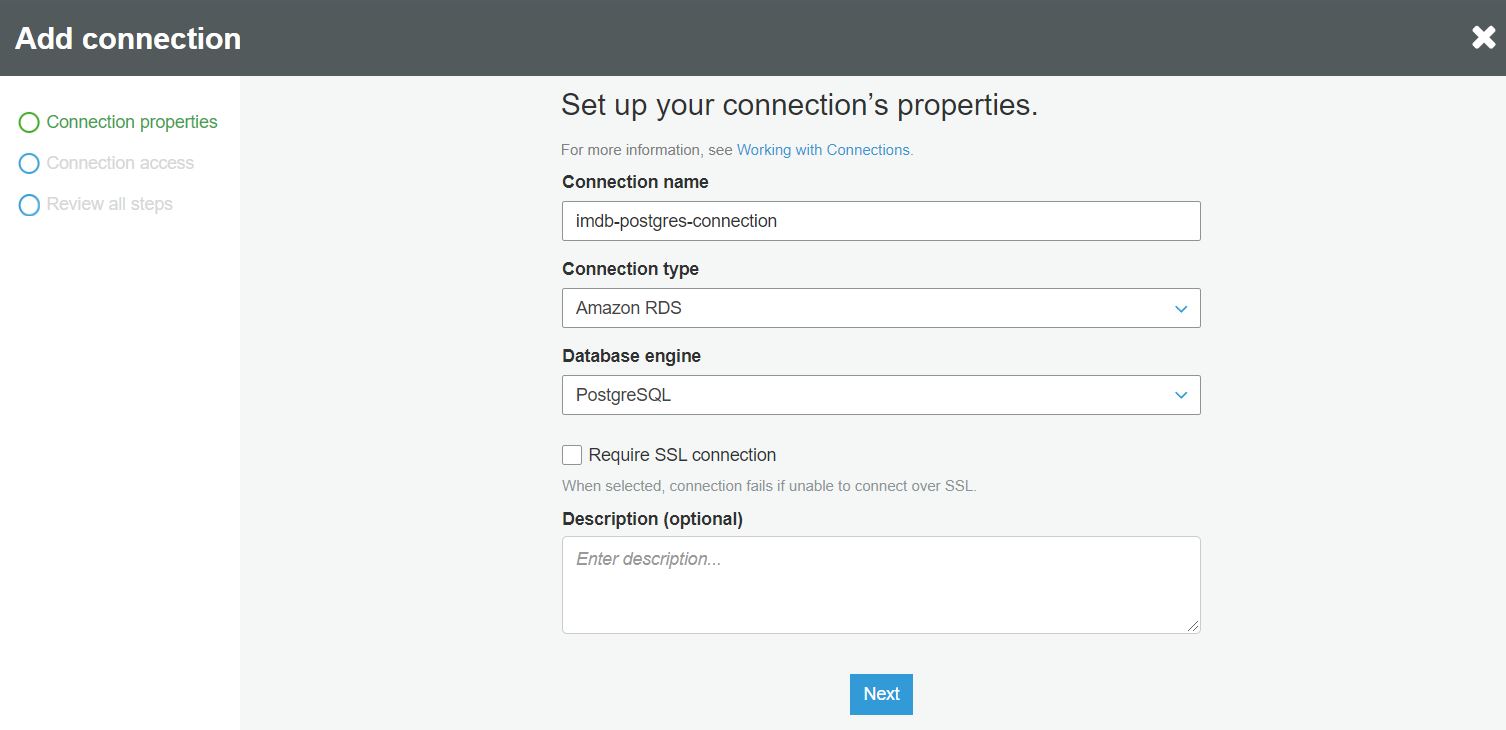
W pierwszym kroku nadajemy nazwę połączenia i definiujemy jego typ oraz silnik bazy danych:
W następnym kroku definiujemy dane połączenia do bazy danych:
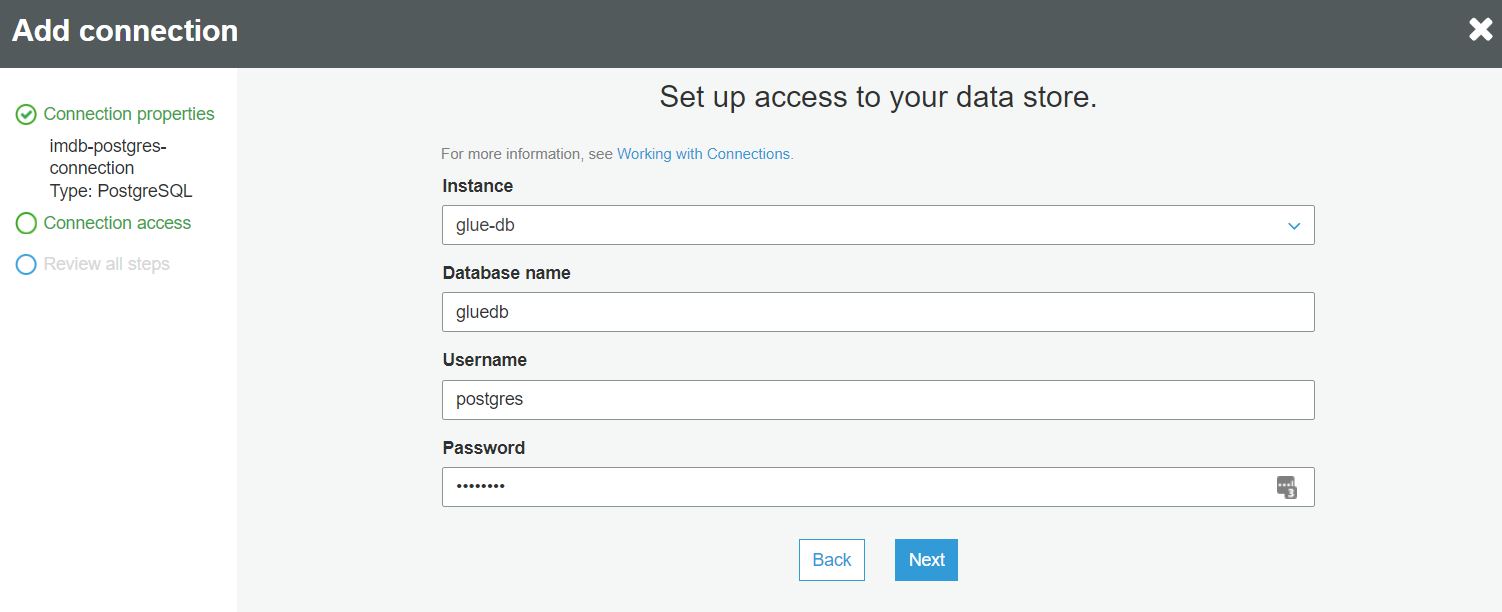
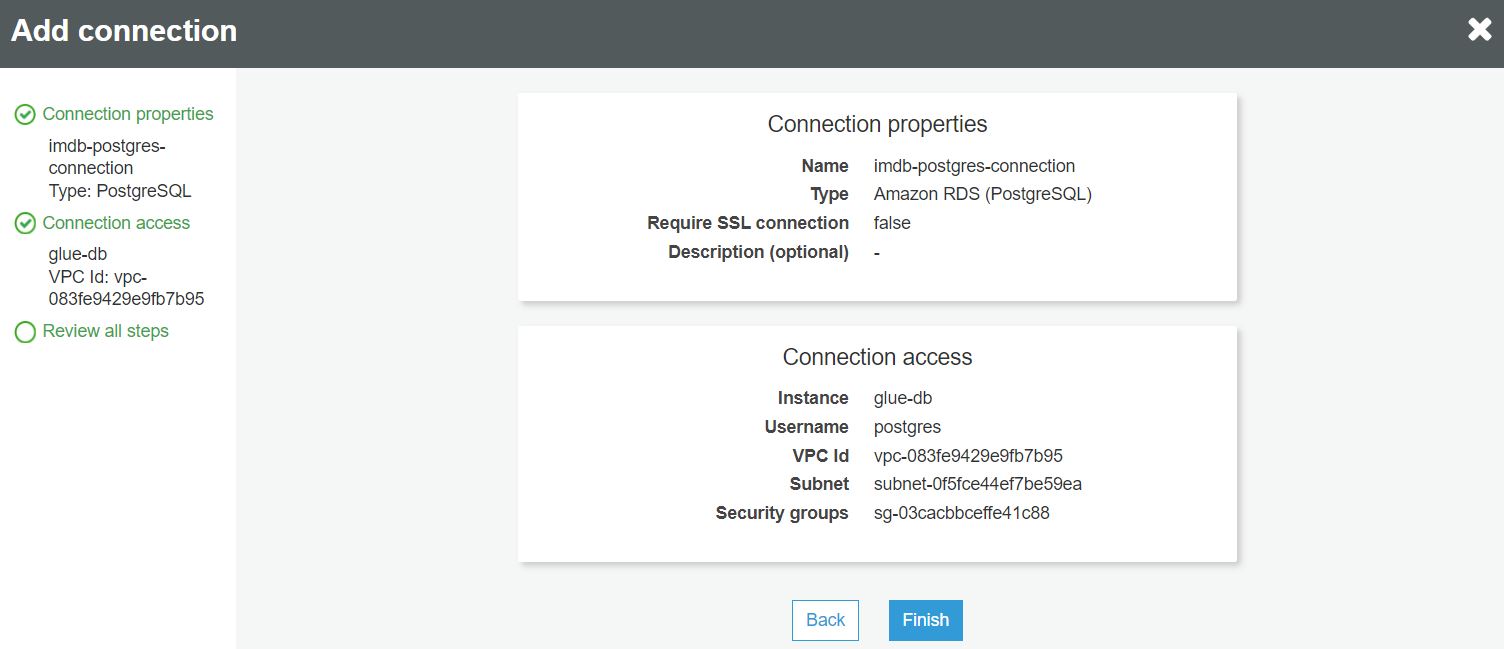
W ostatnim kroku sprawdzamy poprawność wprowadzonych danych i kończymy dodawanie połączenia:
Utworzenie definicji joba AWS Glue
Tworzenie definicji odbywa się w widoku AWS Glue w sekcji Jobs.
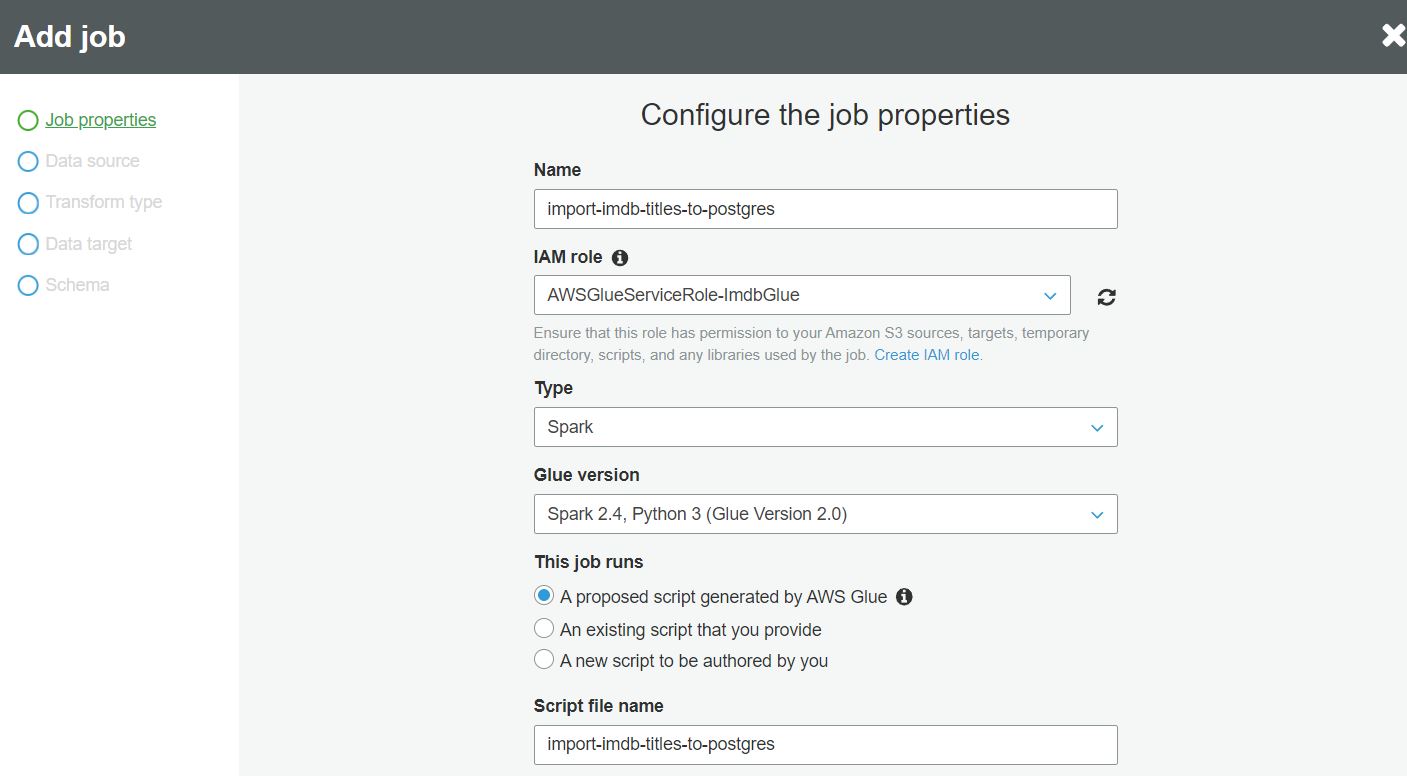
W pierwszym kroku nadajemy nazwę zadania i wybieramy rolę IAM która ma uprawnienia do używanych przez zadanie zasobów. Definiujemy również typ zadania, wersję Glue i skrypt który będzie używany w zadaniu AWS Glue, dane te są domyślnie wypełnione w taki sposób, że AWS Glue wygeneruje skrypt zadania za nas i zapisze go w specjalnie utworzonym buckecie S3.
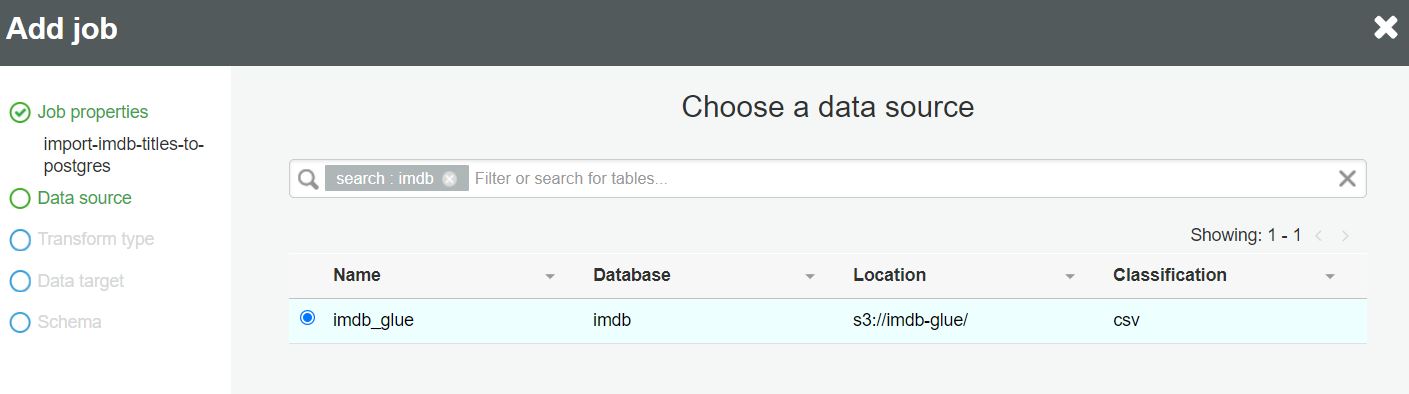
W drugim kroku wybieramy tabelę ze schematem danych do zaimportowania z AWS Glue Data Catalog:
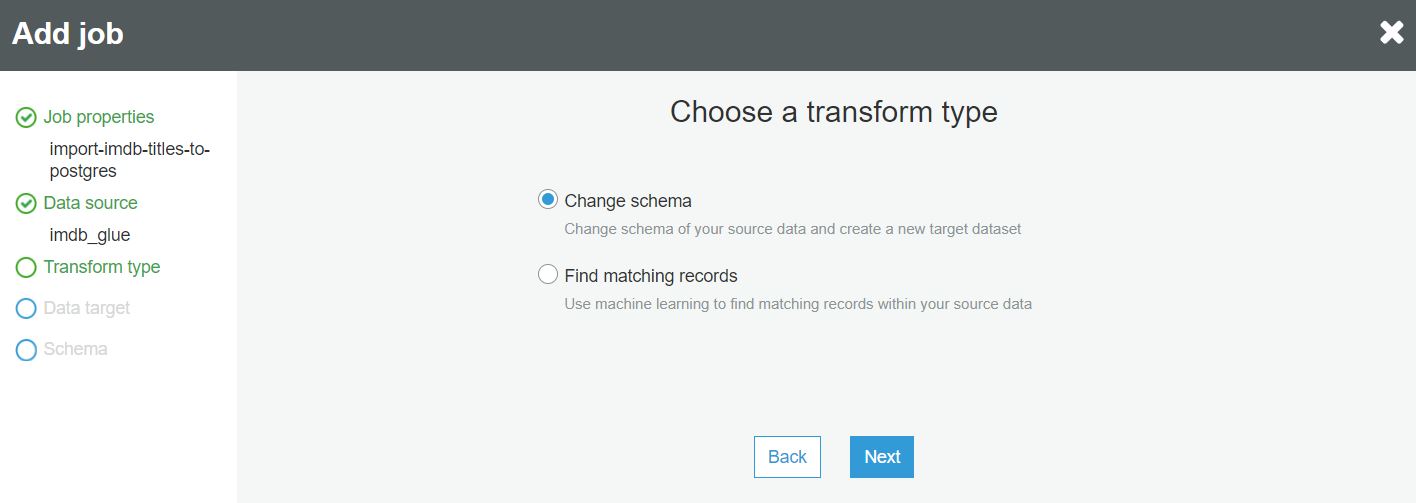
W następnym kroku wybieramy rodzaj transformacji danych:
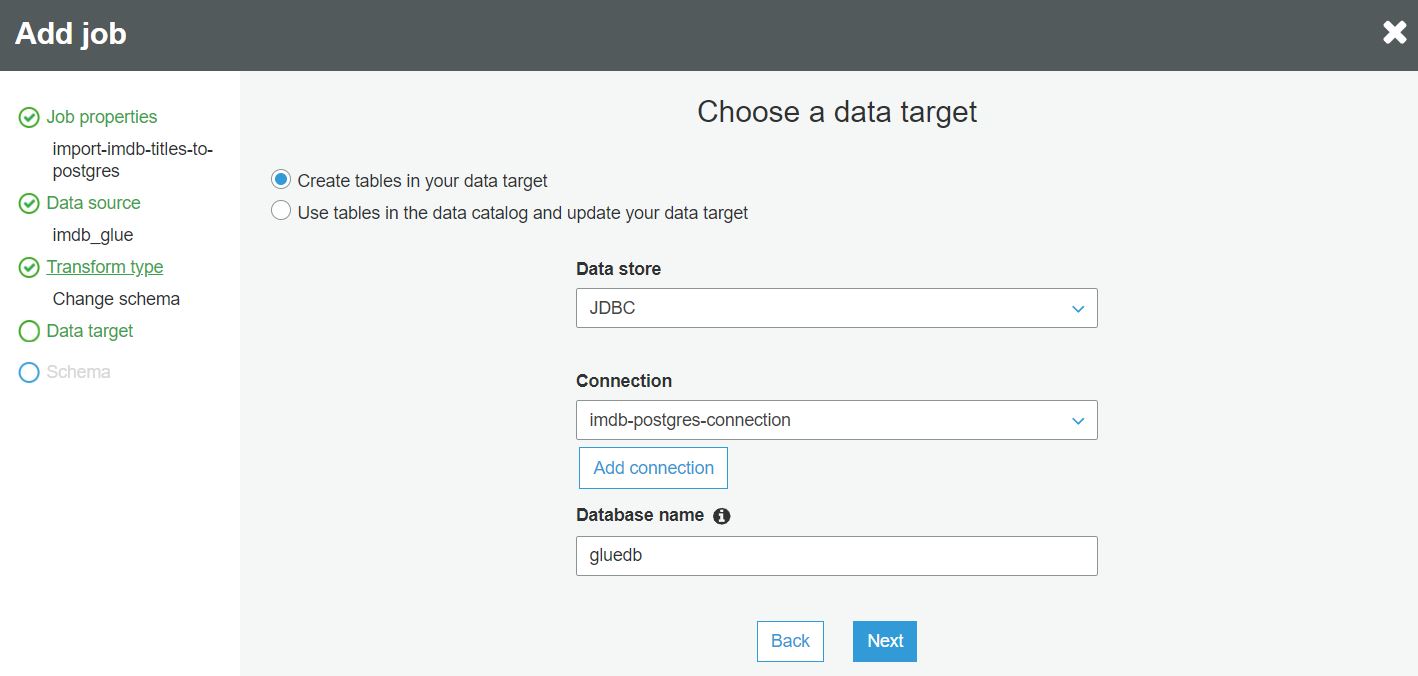
W następnym kroku wybieramy połączenie do docelowej bazy danych Postgres, które utworzyliśmy wcześniej:
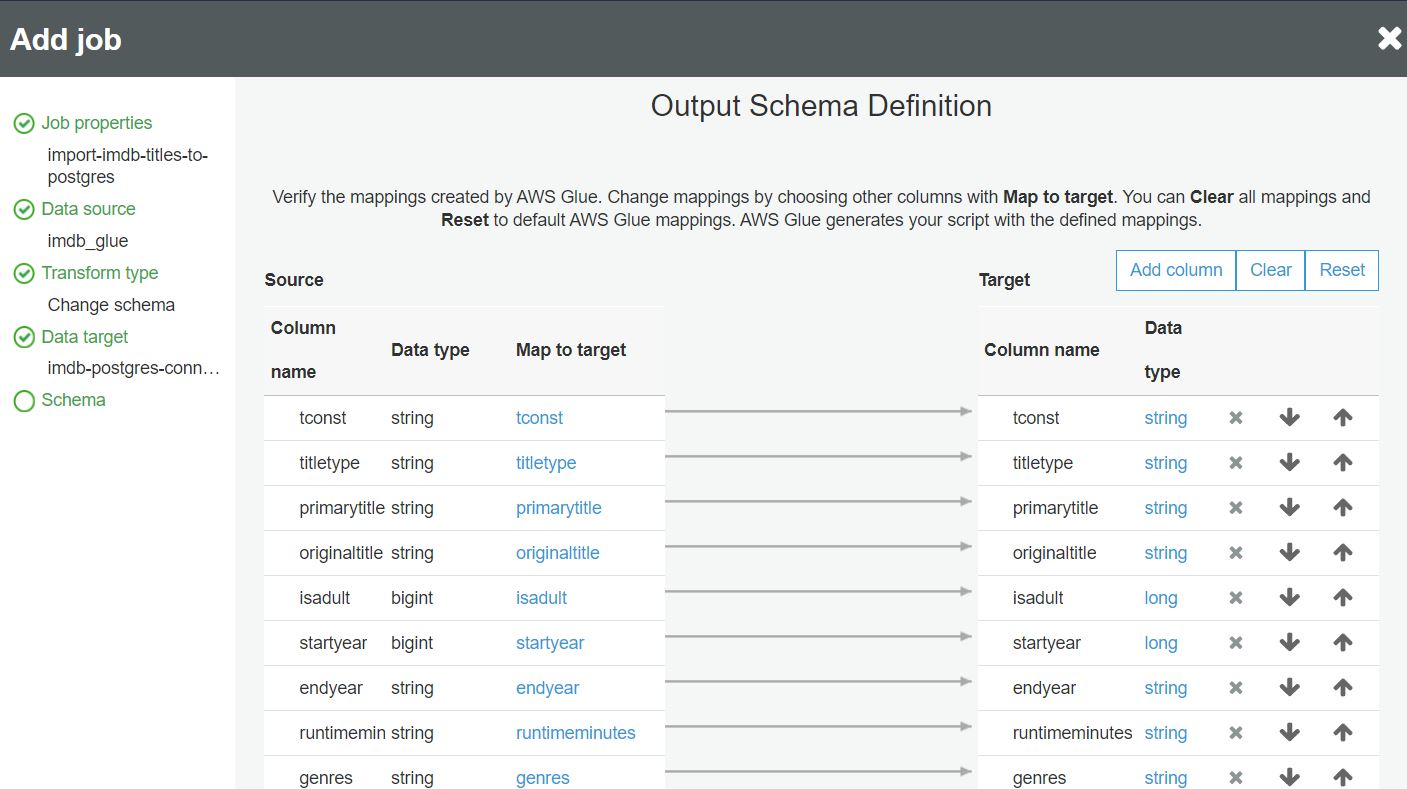
W ostatnim kroku definiujemy mapowanie danych z pliku do kolumn w bazie danych:
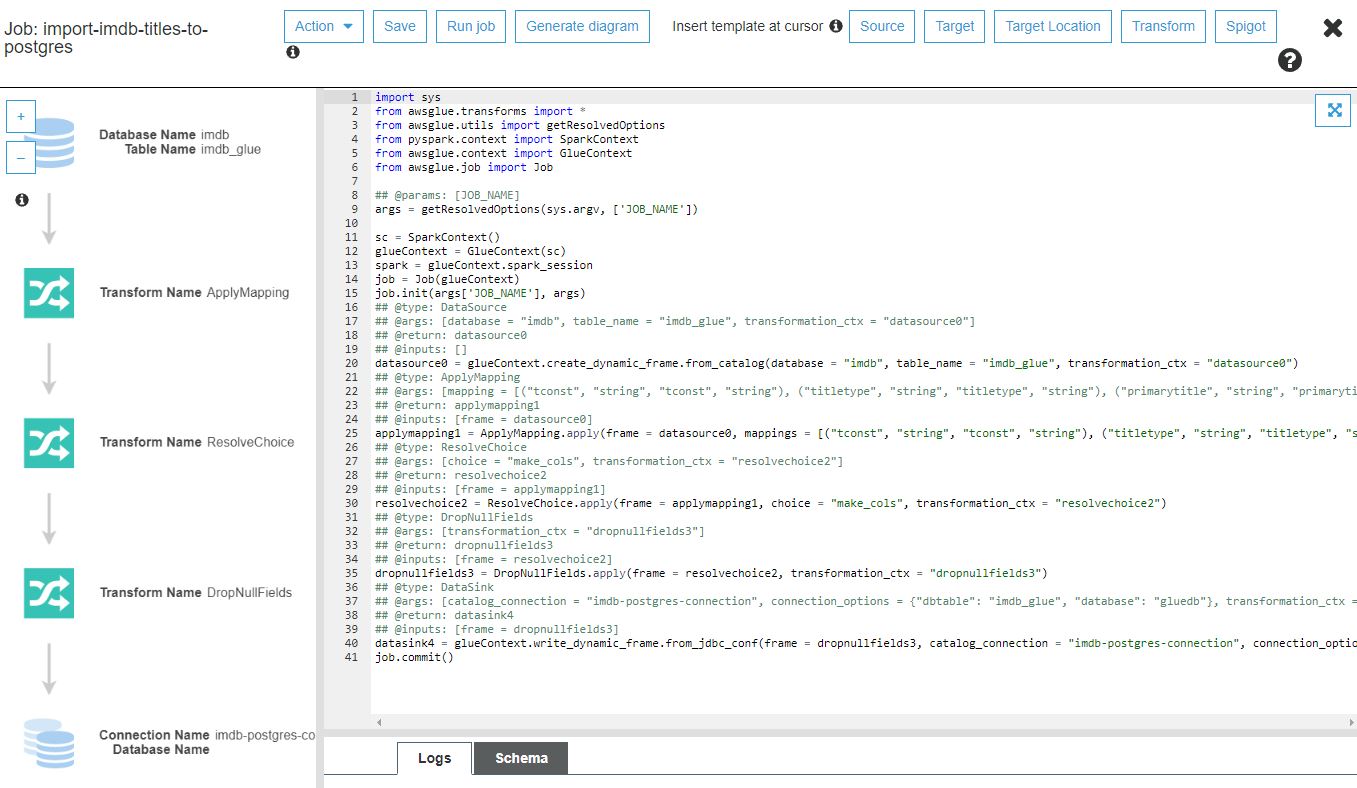
Po naciśnięciu guzika Save job and edit script wygenerowany zostaje skrypt zadania:
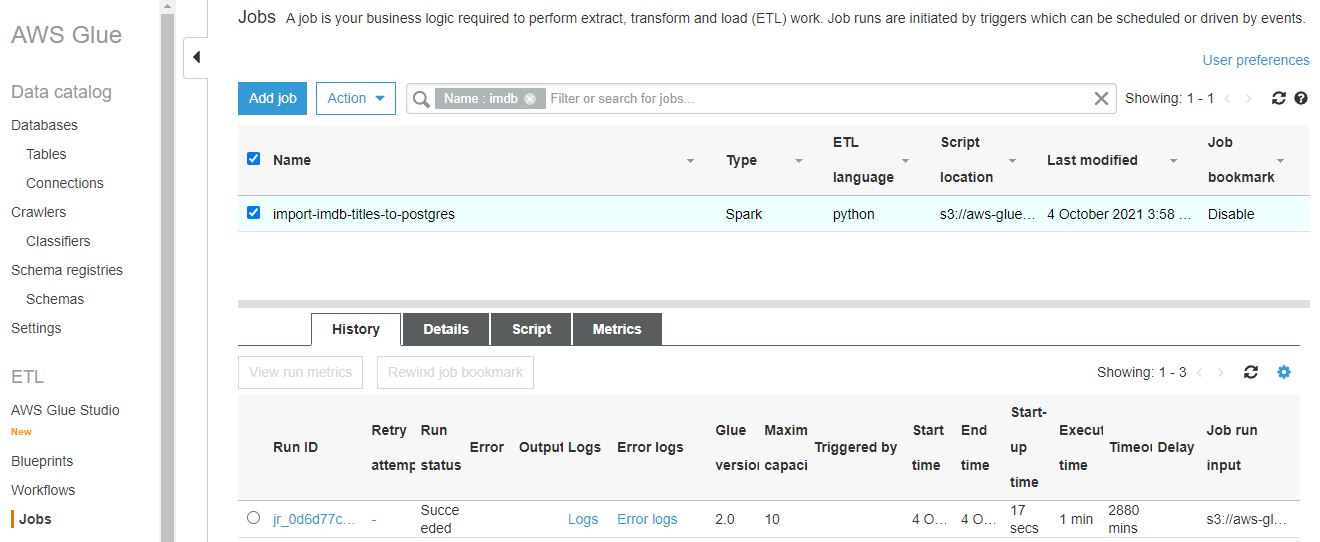
Zadanie możemy uruchomić klikając guzik Run job. Zaznaczając nazwę zadania na liście zadań AWS Glue jobs możemy podejrzeć historię jego uruchomień:
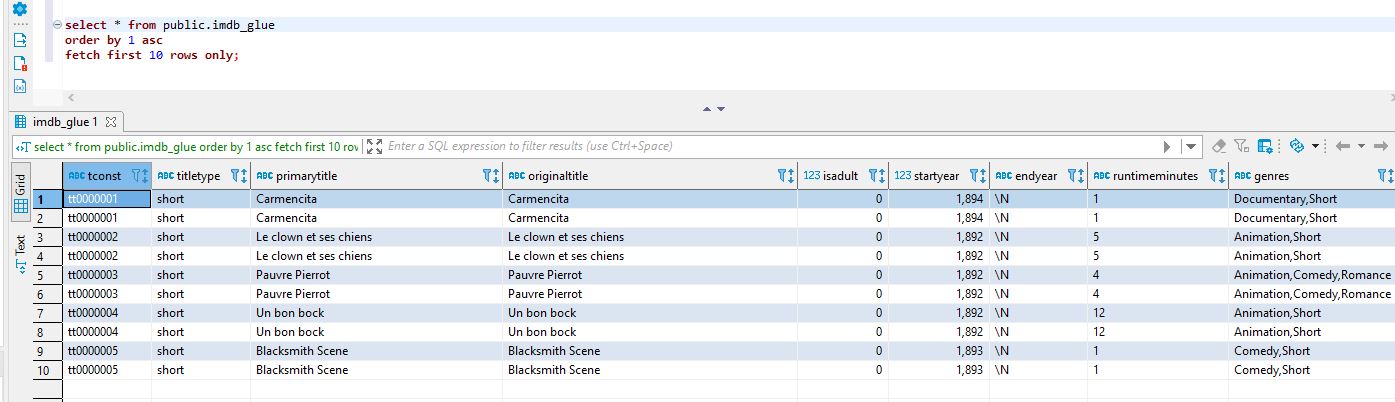
Wyniki działania zadania podejrzeć możemy używając zapytania SQL i ulubionego klienta Postgres:
Plusy i minusy AWS Glue
Plusy:
- AWS Glue jest usługą bezserwerową, więc nie musisz zarządzać zasobami.
- AWS Glue jest łatwy w użyciu i szybki w konfiguracji.
- Nie musisz pisać kodu, ale możesz!
- AWS Glue integruje się z różnymi usługami AWS jako źródłowe lub docelowe punkty końcowe.
- AWS Glue jest dobry we wnioskowaniu schematów danych.
Minusy:
- Nie można kontrolować zasobów obliczeniowych używanych przez AWS Glue.
- Pod maską Glue działa Apache Spark i akceptuje tylko skrypty Python lub Scala.
- Zadania AWS Glue mają zimny czas startu.
Cena AWS Glue
Joby i crawlery AWS Glue są rozliczane według „godziny DPU”, co odpowiada godzinie pracy przy użyciu 4 procesorów wirtualnych i 16 GB pamięci. Koszt 1 DPU (0,44 USD/godz.). Chociaż jednostki DPU są wyceniane godzinowo, rozliczane są co sekundę, z minimum jedną minutą.
AWS Glue Catalog jest wyceniany według liczby skatalogowanych obiektów i liczby żądań do katalogu (pierwszy milion obiektów i żądań miesięcznie jest bezpłatny).